Keras Starting, Stoping, Resuming
Keras Starting, Stoping, Resuming. This is the 1st step to perform when training a model. It is an exploratory approach to identify suitable learning rates. Once we have suitable learning rate we can further continue with initial learning rate finder, cycles, decay schedulers learning rates.



- 1. Warum müssen wir das Training starten, stoppen und fortsetzen?
- 2. Warum nicht die Lernrate-Scheduler oder Lernrate-Decay verwenden?
- 3. Vorteile des ctrl + c-Trainings
- 4. Argparser for model start, stop, resume
- 3. Load training tf dataset
- 4. Load, rescale, reshape images using OpenCV
- 5. Label Binarizer
- 6. Model start or load
- 7. Callbacks
- References
1. Warum müssen wir das Training starten, stoppen und fortsetzen?
Dies ist der 1. Schritt, der beim Training eines Modells erforderlich ist. Es ist ein exploratives Vorgehen, um geeignete Lernraten zu identifizieren. Sobald wir eine geeignete Lernrate haben, können wir weiterhin mit der Genauigkeitanpassung des Modelles anhand initial learning rate, decay and cycle schedulers fortsetzen.
Es gibt eine Reihe von Gründen warum wir das Training eines Modelles starten, stoppen oder fortsetzen müssen. Die beiden Hauptgründe sind:
- Die Trainingssizung wird abgebrochen und das Training wird gestoppt (wegen eines Stromaussfalls, der Überschreitung einer GPU-Sitzung)
- Mann will direkt die Lernrate anpassen -"on the fly"- um die Genauigkeit des Modelles zu verbessern. Dies gescheht normalerweise durch die Verringerung der Lernate um eine Größenordnung
Die Verlustfunktion eines neuronalen Netzwerkes beginnt sehr hoch, fällt aber sehr schnell ab. Die Genugkeit des Modelles ist am Anfang sehr niedrig, steigt aber sehr schenll an. Schließlich erreichen die Genauigkeit und die Verlustfunktion ein Plateau.
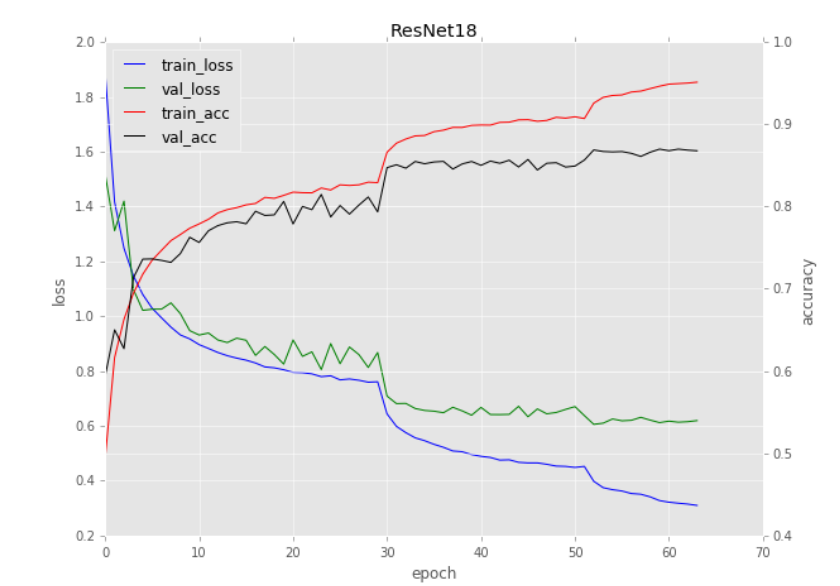
- Die Verlustfunktion beginnt sehr hoch, fällt dann aber schnell ab
- Die Genauigkeit ist anfangs sehr niedrig, steigt dann aber schnell an
- Schließlich erreichen Verlust und Genauigkeit ein Plateau
Was passiert um Epoche 30 herum?
Warum sinkt der Verlust so dramatisch? Und warum steigt die Genauigkeit so gewaltig an?
Der Grund für dieses Verhalten ist:
- Das Training wurde gestoppt
- Die Lernrate wurde um eine Größenordnung herabgesetzt (Für die Lernrate ist die Standardpraxis, sie um eine Größenordnung zu senken)
- Das Training wurde wieder fortgesetzt.
Wir das Training weiter fortgeführt und die Lernrate ständing reduziert, so wird sie schließlich sehr gering sein. Je kleiner die Lernrate ist, desto geringer ist der Einfluss auf die Genauigkeit.
Letztendlich gibt es zwei Probleme:
- Die Lernrate wird sehr klein sein, was wiederum dazu führt dass die Modell-Gewichstsaktualisierungen sehr klein werden und das Modell somit keine sinvollen Forschritte machen kann.
- Wir fangen an, aufgrund der kleinen Lernrate zu überanpassen. Das Modell sinkt im Bereiche mit niedrigen Verlustwerte des Verlustslandschaft an, passt sie übermässig an die Trainingsdaten an und generalisiert sich nicht auf die Validierungsdaten.
2. Warum nicht die Lernrate-Scheduler oder Lernrate-Decay verwenden?
Wann das Ziel darin besteht die Modellgenaugkeit durch das Absenken der Lernrate zu verbessern, warum dann nicht einfach die Lernrate-Scheduler oder die Lernrate-Decay zurückgreifen?
Das Problem ist dass man möglicherweise keine gute Vorstellung von der Scheduler- und Decay Parameterwerten hat:
- Die ungefähre Anzahl der Epochen, für die trainiert werden soll
- Was eine angemessene anfängliche Lernrate ist
- Welcher Lernratenbereich für CLRs verwendet werden soll, die Lernrate anzupassen und das Training an der Stelle fortzuseten an den wir aufgehört haben (Lernrate Schedueler und Decay bitten in Regel es nicht)
3. Vorteile des ctrl + c-Trainings
- Feinere Kontrolle über das Modell
- Bittet die Möglichkeit an das Modell bei einem bestimmten Epoch manuell zu pausieren
- Sobald man ein paar Experimente mit "ctrl + c" dürchgeführt hat, wird man eine gute Vorstellung von den geeigneten PHypaerparametern haben. Wenn das der Fall ist, kann man weiter Lernrate-Scheduler und Lernarte-Decay verwenden um die Genauigkeit des Modelles weiterhin zu erhöhen.
import tensorflow as tf
from tensorflow.keras.datasets import fashion_mnist
import cv2
import argparse
import numpy as np
from resnet import ResNet
from callbacks.epochcheckpoint import EpochCheckpoint
from callbacks.trainingmonitor import TrainingMonitor
import os
import sklearn
import keras.backend as K
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--checkpoints", default = "checkpoints", help="path to output checkpoint directory")
ap.add_argument("-m", "--model", default = "checkpoints/epoch_25.hdf5", type=str, help="path to *specific* model checkpoint to load")
ap.add_argument("-s", "--start-epoch", type=int, default=25, help="epoch to restart training at")
args = vars(ap.parse_args([]))
((trainX, trainY), (testX, testY)) = fashion_mnist.load_data()
print(trainX.shape, trainY.shape, testX.shape, testY.shape)
#resize all images to (32, 32)
trainX = np.array([cv2.resize(image, (32, 32)) for image in trainX])
testX = np.array([cv2.resize(image,(32, 32)) for image in testX])
#scale images between (0, 1)
trainX = trainX.astype("float32")/ 255.
testX = testX.astype("float32")/ 255.
#reshape data to include batch and channel dimensions --> (batch/len(dataset), size1, size2, no_channels)
trainX = trainX.reshape(len(trainX), 32, 32, 1)
testX = testX.reshape(len(testX), 32, 32, 1)
print(trainX.shape, testX.shape, trainY.shape, testY.shape)
from sklearn.preprocessing import LabelBinarizer
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
#trainAug = tf.keras.preprocessing.image.ImageDataGenerator()
if args["model"] == None:
optimizer = tf.keras.optimizers.SGD(lr = 0.001)
loss = tf.keras.losses.BinaryCrossentropy()
model = ResNet.build(32, 32, 1, 10, (9, 9, 9),(64, 64, 128, 256), reg=0.0001)
model.compile(optimizer = optimizer, loss = loss, metrics = ["accuracy"])
else:
print("INFO: loading model", args["model"], "...")
tf.keras.models.load_model(args["model"])
print("INFO lr = {}", format(K.get_value(model.optimizer.lr)))
K.set_value(model.optimizer.lr, 1e-01)
print("INFO lr = {}", format(K.get_value(model.optimizer.lr)))
plotPath = os.path.sep.join(["output", "resnet_fashion_mnist.png"])
jsonPath = os.path.sep.join(["output", "resnet_fashion_mnist.json"])
# construct the set of callbacks
callbacks = [EpochCheckpoint(args["checkpoints"], every=1, startAt=args["start_epoch"]),
TrainingMonitor(plotPath, jsonPath=jsonPath, startAt=args["start_epoch"])]
trainX, trainY = trainX[:64, :, :, :], trainY[:64]
testX, testY = testX[:64, :, :, :], testY[:64]
model.fit(trainX, trainY, batch_size=8,\
validation_data=(testX, testY),\
steps_per_epoch=len(trainX)//16,\
epochs=3, callbacks=callbacks)
print("Done")
References
Adrian Rosebrock, OpenCV Face Recognition, PyImageSearch, https://www.pyimagesearch.com/, accessed on 3 January, 2021> www:https://www.pyimagesearch.com/2019/09/23/keras-starting-stopping-and-resuming-training/